
为何同一玩家在25/50级别会正确弃牌,却在1/2级别面对相同局面时选择跟注?
答案揭示了扑克中最易被利用的优势:人的决策是在优化大脑奖励,而非记分牌期望值(EV)。
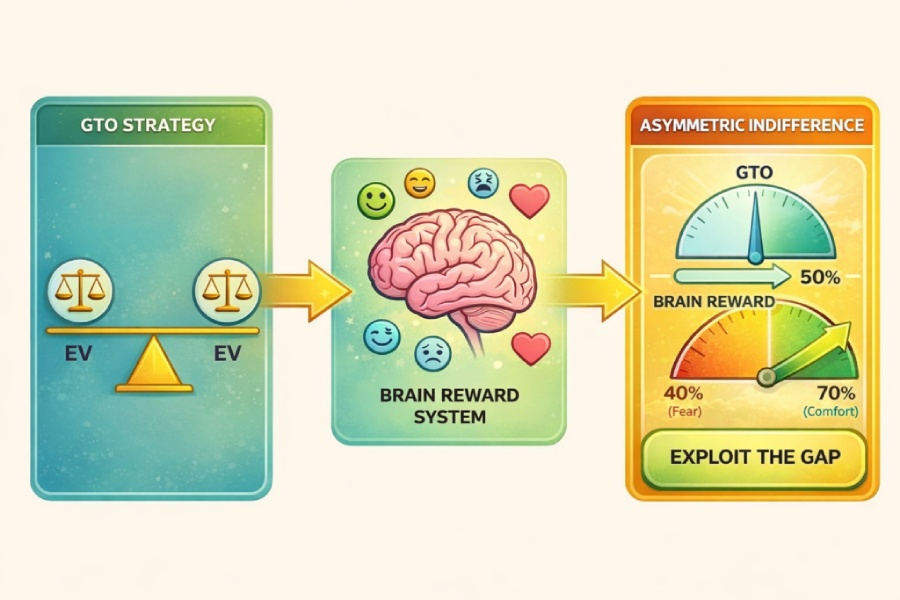
大脑奖励作为最终共同路径
扑克决策源于两股并行力量。其一是策略计算:底池赔率、范围与频率。其二是大脑的奖励系统。
尽管我们在计算底池赔率和范围时,会有意识地以EV为考量,但最终决定却经过了一层过滤——我们预期不同结果将带来何种感受。这包括避免损失的解脱感、做出正确弃牌的满足感、诈唬成功的兴奋,或是英雄式跟注获得印证的自豪。
我将这种内在回报称为预期的“大脑奖励”(有时亦称神经货币)。它是所有输入信息汇聚并最终产生决策的“最终共同路径”。
关键在于,预期的大脑奖励常与实际的大脑奖励不同。例如,我们可能预期“回本”会带来巨大的胜利感,结果却发现一旦实现,情感回报远小于预期。这两者又都与筹码EV不同。重要的是,驱动实时决策的正是预期的大脑奖励。更强的玩家往往能让这种预期更贴近EV,但它永远不会被完全消除。
需注意,这不仅关乎情绪。许多自律的玩家能很好地抑制情绪冲动,却仍会因实际原因偏离筹码EV最优路线——例如为了避免再次取款、保留最后一份买入,或锁定盈利的战绩。大脑奖励包含筹码之外的所有效用来源,无论是情感上的、实际上的,还是个人层面的。
不对称的漠视
这引出了不对称的漠视:即系统性地偏离GTO平衡点,但这并非错误,而是基于大脑奖励而非纯粹筹码EV的理性优化。
它通常以两种形式呈现:
个体不对称:玩家大脑奖励的优先级导致其出现一贯的个人化偏离。放弃一个略微+EV的机会以避免波动或压力并非不理性,这是在用舒适度优化替代筹码优化。
角色反转不对称:同一玩家在下注与跟注时可能拥有不同的漠视点,因为在这两种角色中,风险的心理框架是不同的。
这种不对称创造了可被利用的缺口,而仅凭游戏理论无法预测这些缺口。

推离式剥削框架
举例而言,GTO的河牌策略常试图让对手陷入“漠视”。面对真人玩家时,这个目标并不得当。相反,我们应该利用大脑奖励驱动的偏离,将对手从他们的漠视点推离,使其做出对我们有利的决策。
例1:对抗跟注站的价值下注
GTO漠视点:半个底池的下注会使他们在跟注与弃牌间无差异。
他们的大脑奖励漠视点:由于跟注并猜对的感觉很好,他们可能直到下注量约达70%底池时才感到无差异。
最优剥削:下注65%底池。
结果:他们继续用更差的牌跟注,而你则榨取了更多价值。你刻意不让他们陷入漠视,而是让他们停留在“跟注区”。
例2:对抗厌恶风险的弱手诈唬
GTO漠视点:需要一个大额下注才能让抓诈唬牌陷入无差异。
他们的大脑奖励漠视点:害怕跟注并出错的恐惧可能将那个阈值压得更低,或许在40%底池左右。
最优剥削:诈唬下注45%底池。
结果:他们会弃掉那些理论上跟注有利的牌,同时当他们持有会跟注更大下注的牌时,我们的损失也更少。
原则:识别对手大脑奖励的漠视点位于何处,然后调整你的下注尺度,以利用该点与GTO漠视点之间的差距。
动态的漠视点
这些漠视点并非固定不变。它们会随着疲劳程度、近期输赢和比赛动态而偏移。遭遇Bad Beat后,有些玩家会过度跟注。深夜时分,另一些玩家则弃牌过频。
具体的阈值在移动,但很少完全消失。你在牌桌上获得的优势,正来自于洞察那个阈值此刻位于何处。
结论
“不对称的漠视”解释了为何GTO能击败人类,但无法实现最大程度剥削。人类优化的并非纳什均衡,而是大脑奖励。每位玩家都有可被探知的漠视点,它们由心理状态、具体情境和对风险的承受度所塑造。
扑克的目标并非让对手对你的行动感到无差异,而是识别他们的漠视点与数学计算出的漠视点在何处不同,并将他们从那里推开,直到其决策错误让他们付出筹码代价。
GTO追求平衡。而作为扑克玩家,我们应寻求利用数学上的漠视与人类大脑奖励的漠视之间的不平衡。






